This article will quickly guide you on resolution of the error “kube-system coredns crashloopbackoff” in kubernetes.
{kind=link}
Basically coredns acts as as a basic DNS service in the kubernetes system. In case you want to explore more about this service please follow this link.
About the error:
Basically whenever you are firing up the command on the kubernetes server you are encountered with following “kube-system coredns crashloopbackoff” output.
$ kubectl get pods --all-namespaces NAMESPACE NAME READY STATUS RESTARTS AGE kube-system coredns-66bff467f8-mgqh2 0/1 CrashLoopBackOff 1 4m36s kube-system coredns-66bff467f8-wdtkr 0/1 CrashLoopBackOff 1 4m36s kube-system etcd-kubemaster 1/1 Running 0 4m43s kube-system kube-apiserver-kubemaster 1/1 Running 0 4m43s kube-system kube-controller-manager-kubemaster 1/1 Running 0 4m43s kube-system kube-flannel-ds-amd64-7cn87 1/1 Running 0 39s kube-system kube-proxy-wgjk6 1/1 Running 0 4m36s kube-system kube-scheduler-kubemaster 1/1 Running 0 4m43
Now in order to resolve this error simply follow below two steps:
Step1: Use the following command;
root@kubemaster$ kubectl -n kube-system edit configmap coredns
This will opened with open up with following output on the screeen as below:
# Please edit the object below. Lines beginning with a '#' will be ignored,
# and an empty file will abort the edit. If an error occurs while saving this file will be
# reopened with the relevant failures.
#
apiVersion: v1
data:
Corefile: |
.:53 {
errors
health {
lameduck 5s
}
ready
kubernetes cluster.local in-addr.arpa ip6.arpa {
pods insecure
fallthrough in-addr.arpa ip6.arpa
ttl 30
} prometheus :9153
forward . /etc/resolv.conf
cache 30
#loop <-------
reload
loadbalance
}
kind: ConfigMap
Now just find the “loop” word in it and hashed it or remove it. I just made arrow on the above output to make it clear for you. Save and quit using normal vi command “:wq!”.
Step2: Now remove the old created coredns pods so that new one will be automatically created.
root@kubemaster$ kubectl -n kube-system delete pod -l k8s-app=kube-dns pod "coredns-66bff467f8-mgqh2" deleted pod "coredns-66bff467f8-wdtkr" deleted
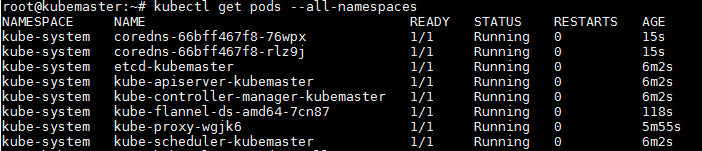
That’s it you are done with the recovery simply wait for one or two minutes to recreate the coredns pods with running state as below;
{kind=link}
root@kubemaster$ kubectl get pods --all-namespaces NAMESPACE NAME READY STATUS RESTARTS AGE kube-system coredns-66bff467f8-76wpx 1/1 Running 0 15s kube-system coredns-66bff467f8-rlz9j 1/1 Running 0 15s kube-system etcd-kubemaster 1/1 Running 0 6m2s kube-system kube-apiserver-kubemaster 1/1 Running 0 6m2s kube-system kube-controller-manager-kubemaster 1/1 Running 0 6m2s kube-system kube-flannel-ds-amd64-7cn87 1/1 Running 0 118s kube-system kube-proxy-wgjk6 1/1 Running 0 5m55s kube-system kube-scheduler-kubemaster 1/1 Running 0 6m2s
View Comments (2)
Thanks for this article.
I solved the same error on my kind cluster with this steps.
Thank you Nielson for your feedback!